Schema is a logical description of the entire database. It includes the name and description of records of all record types including all associated data-items and aggregates. Much like a database, a data warehouse also requires to maintain a schema. A database uses relational model, while a data warehouse uses Star, Snowflake, and Fact Constellation schema.
What Is a Star Schema?
A star schema model can be depicted as a simple star: a central table contains fact data and multiple tables radiate out from it, connected by the primary and foreign keys of the database. In a star schema implementation, Warehouse Builder stores the dimension data in a single table or view for all the dimension levels.
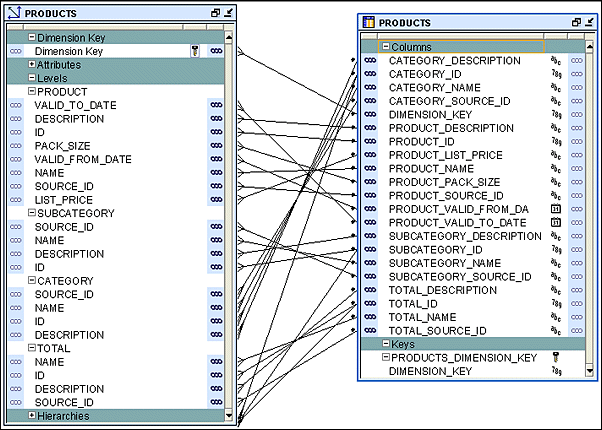
For example, if you implement the Product dimension using a star schema, Warehouse Builder uses a single table to implement all the levels in the dimension, as shown in the screenshot. The attributes in all the levels are mapped to different columns in a single table called PRODUCT.
What Is a Snowflake Schema?
The snowflake schema represents a dimensional model which is also composed of a central fact table and a set of constituent dimension tables which are further normalized into sub-dimension tables. In a snowflake schema implementation, Warehouse Builder uses more than one table or view to store the dimension data. Separate database tables or views store data pertaining to each level in the dimension.
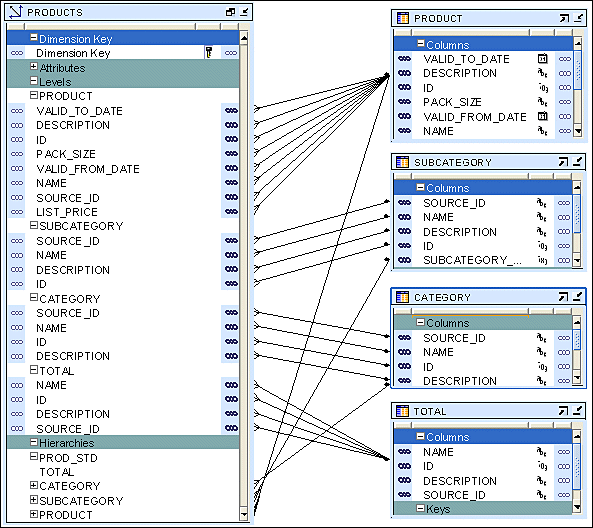
The screenshot displays the snowflake implementation of the Product dimension. Each level in the dimension is mapped to a different table.
key differences in snowflake and star schema
1. Data optimization:
Snowflake model uses normalized data, i.e. the data is organized inside the database in order to eliminate redundancy and thus helps to reduce the amount of data. The hierarchy of the business and its dimensions are preserved in the data model through referential integrity.

Figure 1 – Snow flake model
Star model on the other hand uses de-normalized data. In the star model, dimensions directly refer to fact table and business hierarchy is not implemented via referential integrity between dimensions.

Figure 2 – Star model
2. Business model:
Primary key is a single unique key (data attribute) that is selected for a particular data. In the previous ‘advertiser’ example, the Advertiser_ID will be the primary key (business key) of a dimension table. The foreign key (referential attribute) is just a field in one table that matches a primary key of another dimension table. In our example, the Advertiser_ID could be a foreign key in Account_dimension.
In the snowflake model, the business hierarchy of data model is represented in a primary key – Foreign key relationship between the various dimension tables.
In the star model all required dimension-tables have only foreign keys in the fact tables.
3. Performance:
The third differentiator in this Star schema vs Snowflake schema face off is the performance of these models. The Snowflake model has higher number of joins between dimension table and then again the fact table and hence the performance is slower. For instance, if you want to know the Advertiser details, this model will ask for a lot of information such as the Advertiser Name, ID and address for which advertiser and account table needs to be joined with each other and then joined with fact table.
The Star model on the other hand has lesser joins between dimension tables and the facts table. In this model if you need information on the advertiser you will just have to join Advertiser dimension table with fact table.
4. ETL
Snowflake model loads the data marts and hence the ETL job is more complex in design and cannot be parallelized as dependency model restricts it.
The Star model loads dimension table without dependency between dimensions and hence the ETL job is simpler and can achieve higher parallelism.
This brings us to the end of the Star schema vs Snowflake schema debate. But where exactly do these approaches make sense?
Where do the two methods fit in?
With the snowflake model, dimension analysis is easier. For example, ‘how many accounts or campaigns are online for a given Advertiser?’
The star schema model is useful for Metrics analysis, such as – ‘What is the revenue for a given customer?’
When do you use Snowflake Schema Implementation?
Ralph Kimball, the data warehousing guru, proposes three cases where snowflake implementation is not only acceptable but is also the key to a successful design:
- Large customer dimensions where, for example, 80 percent of the fact table measurements involve anonymous visitors about whom you collect little detail, and 20 percent involve reliably registered customers about whom you collect much detailed data by tracking many dimensions.
- Financial product dimensions for banks, brokerage houses, and insurance companies, because each of the individual products has a host of special attributes not shared by other products
- Multi enterprise calendar dimensions because each organization has idiosyncratic fiscal periods, seasons, and holidays
Ralph Kimball recommends that in most of the other cases, star schemas are a better solution. Although redundancy is reduced in a normalized snowflake, more joins are required. Kimball usually advises that it is not a good idea to expose end users to a physical snowflake design, because it almost always compromises understandability and performance.


1 comments:
nice information .........................!
micro strategy certification training
Post a Comment